The Shift Toward Inference, Part 1: From Training Clusters to Inference Infrastructure
How AI’s center of gravity is moving from model training to model serving. Why GPUs, memory, power, and data centers are becoming the real bottlenecks. And why the next AI race is about running intelligence at scale.
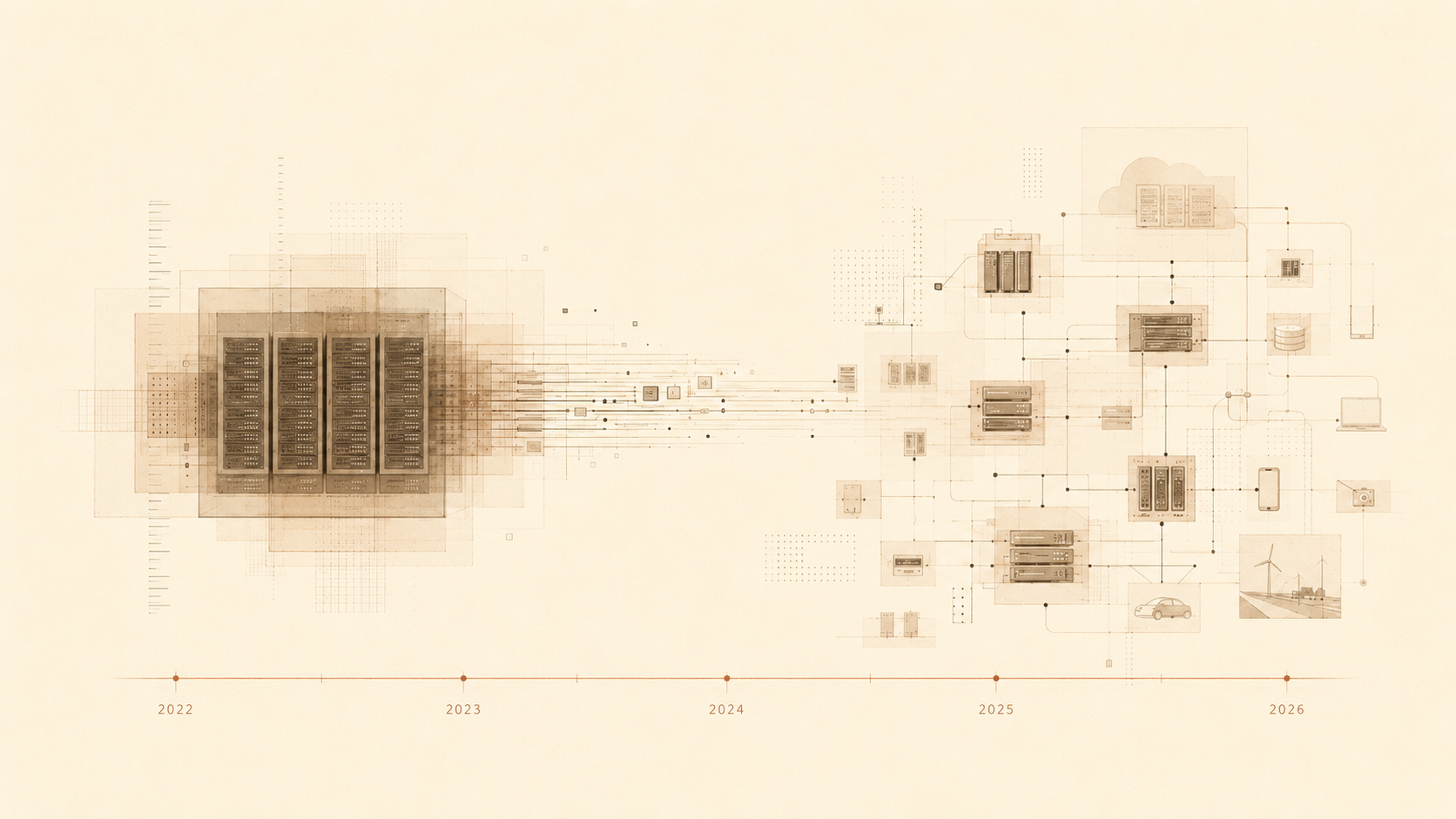
The next phase of AI will not be decided only by who trains the largest model. It will be decided by who can run intelligence at scale. That means the frontier is moving outward. It is in GPUs and HBM, but also in memory systems, power contracts, data-center locations, model routers, inference compilers, quantization techniques, agent frameworks, audit logs, and governance processes. Training created the models. Inference will decide how deeply those models enter the economy. The AI race is becoming less like a one-time scientific contest and more like an infrastructure buildout. The companies and countries that win will be the ones that can turn intelligence into a reliable, affordable, governed utility.
Hardware Layer: From Bigger GPUs to Inference Infrastructure
During the early generative AI boom, hardware demand was driven primarily by training. The focus was on building massive GPU clusters to train frontier models, and hardware was viewed mainly as the engine of model creation. As AI moves into everyday products, enterprise workflows, copilots, search, agents, and consumer devices, the challenge is no longer just training models, rather, it is serving intelligence continuously. Every prompt, generated token, tool call, agent step, and coding suggestion becomes an inference workload. Inference runs constantly and is likely to grow further as companies push more agentic and loop-based workflows.
This changes what matters in AI hardware. In the training era, the question was how much compute could be concentrated into a cluster. In the inference era, the focus shifts to how many useful tokens can be served per second, per watt, and per dollar. That is why recent hardware launches are increasingly positioned as inference systems rather than simply faster GPUs.
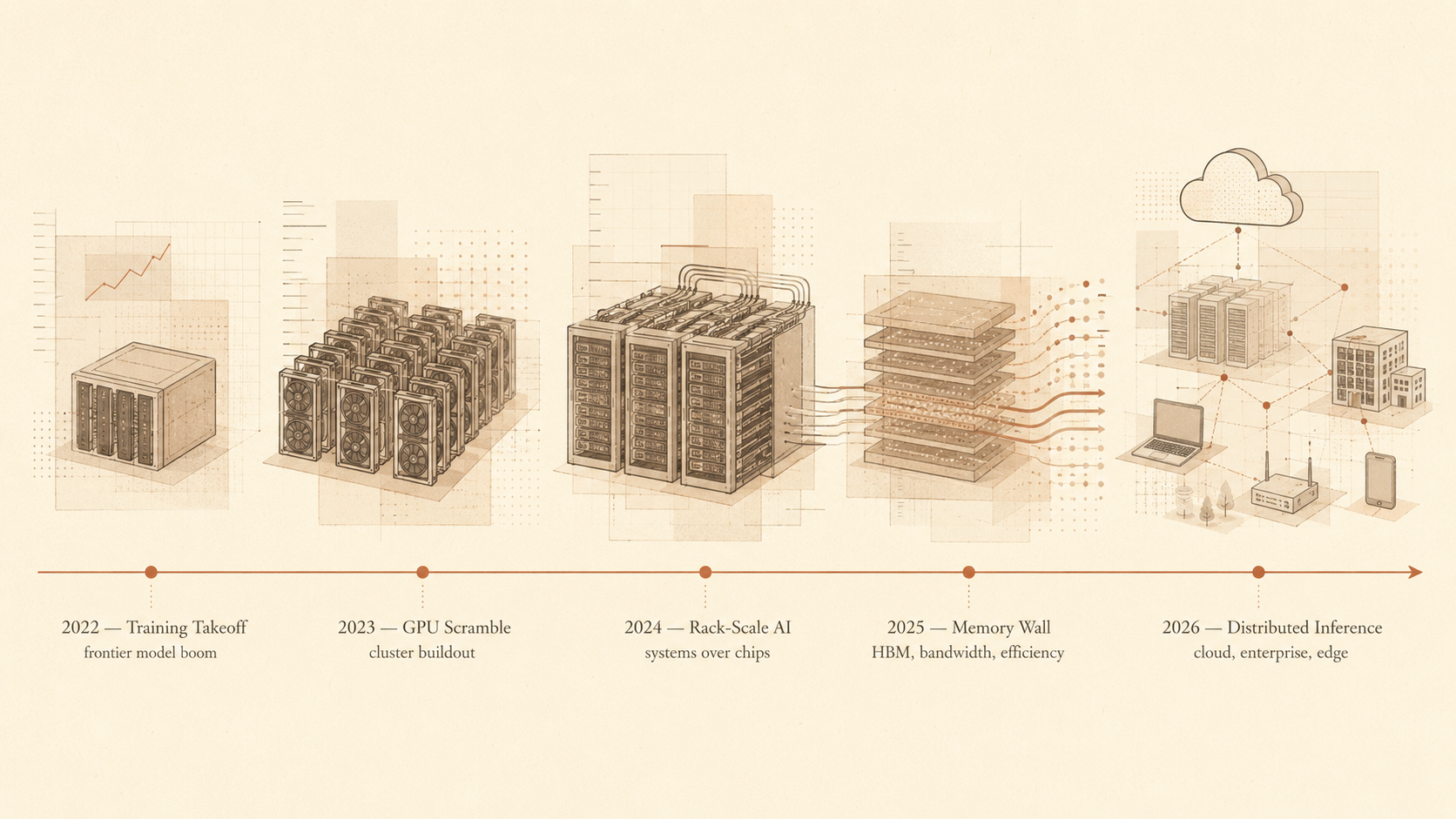
NVIDIA’s Blackwell platform illustrates this shift. The GB200 NVL72 system was marketed around real-time large language model inference, emphasizing improvements in speed, efficiency, and cost. NVIDIA’s Rubin and Vera Rubin roadmap extends this vision, framing future infrastructure as “AI factories” designed to produce intelligence at scale. The unit of competition is no longer just the GPU—it is the entire system: racks, networking, memory, cooling, power, and data centers. The same trend is visible among hyperscalers. AWS has Trainium, Google has TPUs, Microsoft has Maia, and AMD continues to expand its Instinct accelerator lineup. While their approaches differ, the goal is similar: gain greater control over the economics of inference.
Those economics increasingly depend on memory as much as compute. Large models, long-context windows, KV caches, and agentic workflows all place heavy demands on memory bandwidth and capacity. Inference at scale is therefore a memory and systems problem, not just a chip problem—a reality reflected in rising demand for high-bandwidth memory and broader memory pricing pressures.
Power is the other major constraint. Inference workloads run continuously, which means continuous electricity consumption. As AI becomes embedded across software, search, customer service, productivity tools, and autonomous systems, data-center power requirements become a strategic issue. In many cases, the limiting factor may not be chip availability but access to electricity, cooling infrastructure, and grid capacity. This also helps explain why inference may become more distributed than training. Training can remain centralized in a handful of massive clusters, but inference is latency-sensitive. Whether helping someone write code, make a purchase, or interact with software, AI systems need to respond quickly. That creates pressure to place inference capacity closer to users, enterprise data, and increasingly on edge devices.
Apple’s emphasis on on-device AI reflects this trend, while Google’s integration of Gemini across Search, Android, and Workspace creates inference demand across billions of interactions. The future of AI infrastructure is therefore likely to be layered: cloud inference, regional inference, enterprise inference, and on-device inference working together. The implication is that AI hardware is becoming more specialized and strategic. GPUs remain critical, but the broader stack now includes custom accelerators, TPUs, inference chips, HBM, advanced networking, rack-scale systems, liquid cooling, edge devices, and power infrastructure.The winners will be the companies that can deliver intelligence most efficiently. That is the core hardware transition from 2022 to 2026 -- moving from optimizing model training to making token generation cheaper, faster, and scalable enough to be everywhere.
Sources
https://www.deloitte.com/us/en/what-we-do/capabilities/applied-artificial-intelligence/content/state-of-ai-in-the-enterprise.html
https://nvidianews.nvidia.com/news/nvidia-blackwell-platform-arrives-to-power-a-new-era-of-computing
https://www.apple.com/newsroom/2026/06/apple-intelligence-brings-powerful-ai-capabilities-into-everyday-experiences/
https://security.apple.com/blog/expanding-pcc/