The Shift Toward Inference, Part 2: From Bigger Models to Smarter Systems
AI software stack is evolving from simple model serving into a cost-aware system of routers, caches, runtimes, and reasoning policies. Knowing when to spend compute, when to save it, and how to make every token cheaper will increasingly become important.
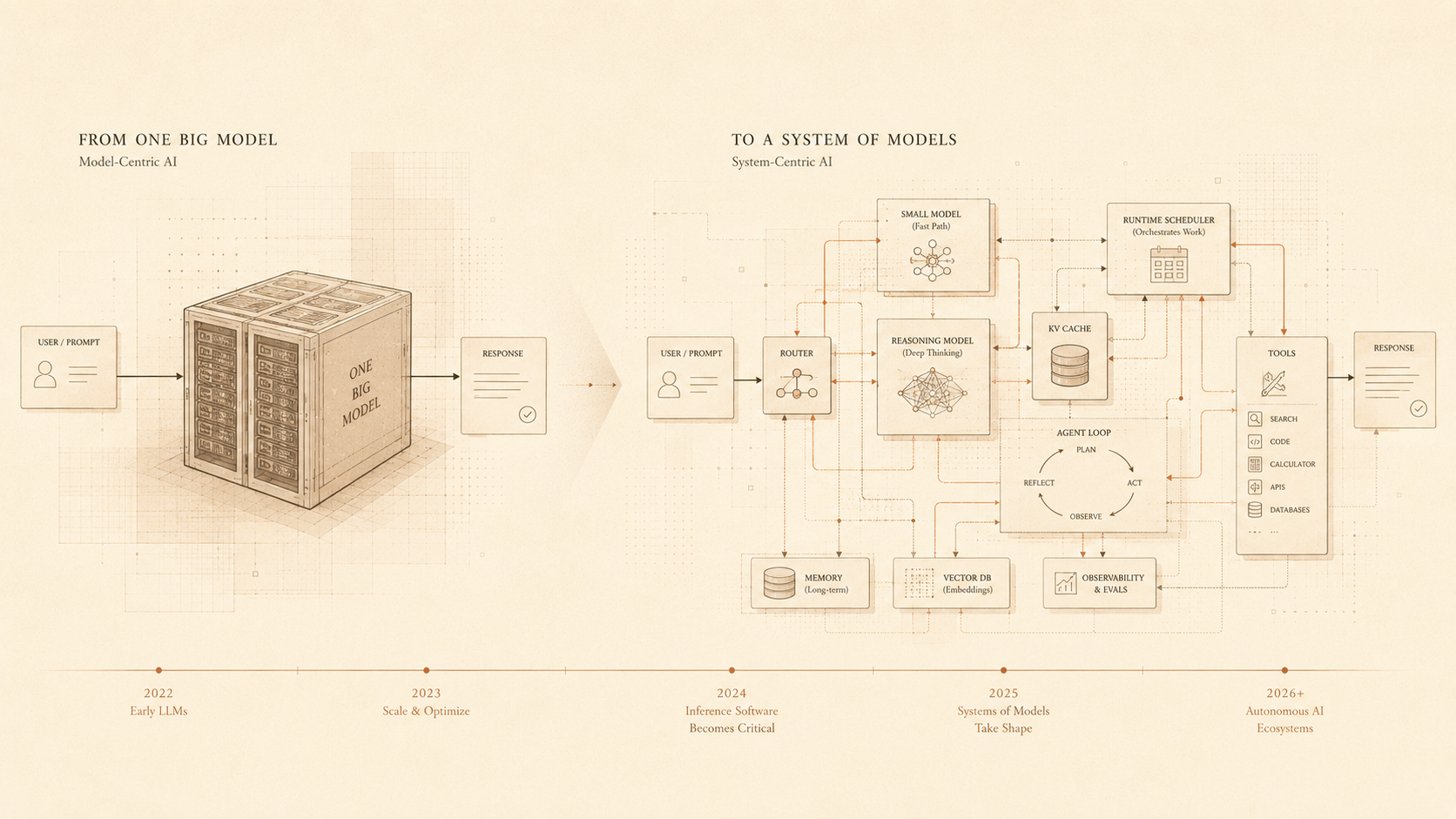
In the previous part, we discussed a how the hardware layer is shifting from training to inference. In this second part of the series, we will deep dive into shifts at the software layer.
Making inference cheaper by optimizing software
As AI systems move from research demos into real products, the state-of-the-art model is not useful if it is too slow, too expensive, or too memory-hungry to serve at scale. This is where the software layer becomes critical. The software stack is now being redesigned around one central goal of reducing the cost of intelligence without reducing its usefulness. For AI products to keep users engaged and turn interactions into meaningful outcomes, responses must be both fast and useful. That means making models smaller where possible, activating only the parts of a model that are needed, compressing memory, reusing previous computation, routing requests intelligently, and spending more compute only when the task truly requires it.
With models like OpenAI’s o1, the industry started treating inference itself as a place where intelligence can improve. Instead of making the model better only during training, the model can spend more time “thinking” during inference, especially for harder tasks. Recent research on model routing and cognitive architectures reinforces this trend. RouteLLM, for example, shows that intelligently routing queries between smaller and larger models can significantly reduce inference costs while maintaining comparable quality. This points toward a new cognition layer: one that decides which model, tool, or execution path should handle a given task.
In the training era, the equation was more pretraining compute meant more intelligence. In the inference era now, more intelligence can also mean selectively spending more compute at response time. A simple summarization request may need a fast, cheap answer. A complex coding, math, legal, or planning task may justify more reasoning steps. This turns inference into an adaptive system rather than a fixed execution pass. If models spend more time reasoning, inference becomes more expensive. The software stack must therefore decide when to spend compute and when to save it. Not every request deserves the same model, the same context window, or the same reasoning budget. This is why model routing, dynamic compute allocation, and task-aware serving are becoming more important.
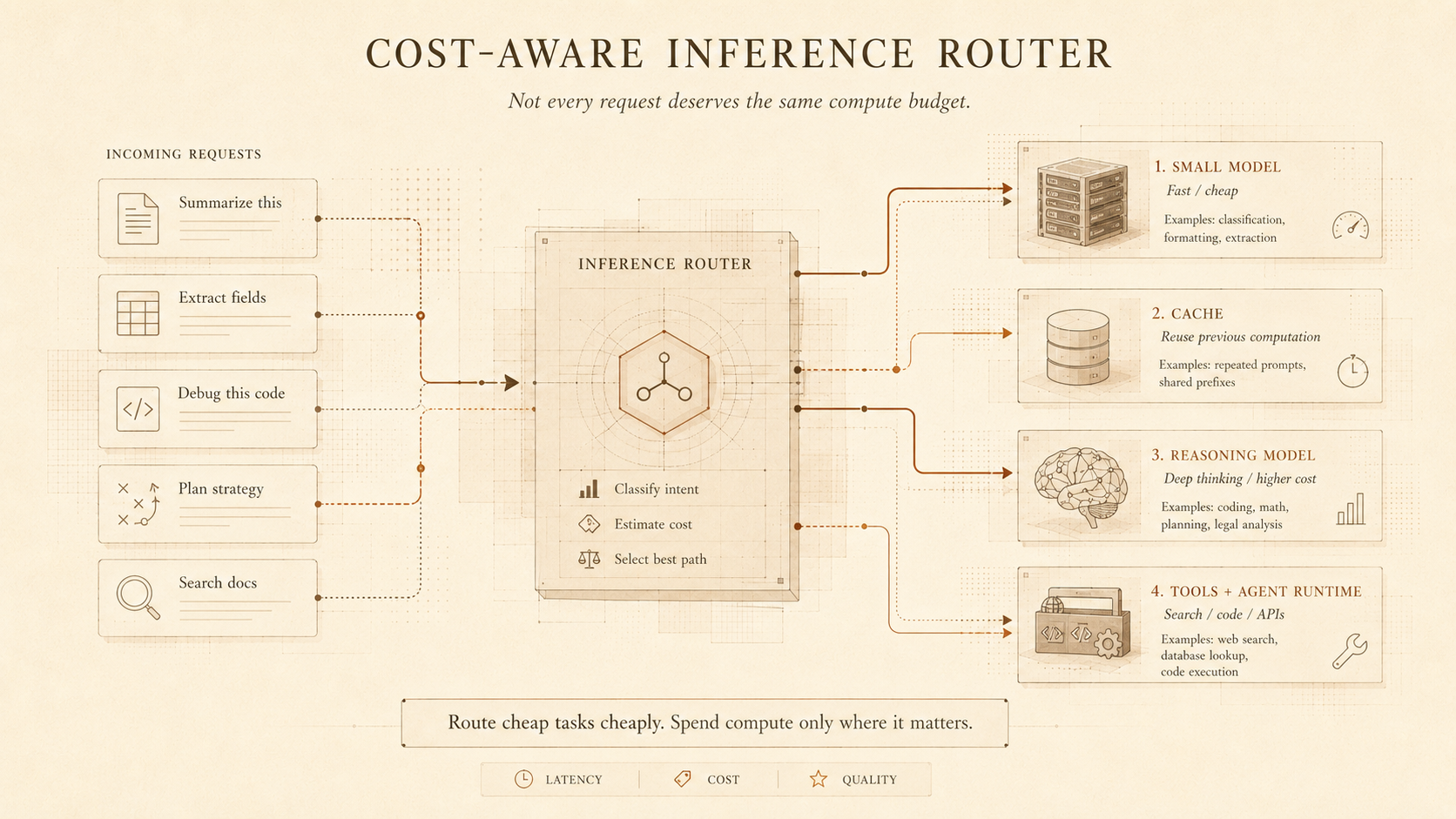
Another important trend is sparsity, especially through mixture-of-experts models. In a dense model, much of the model may be active for every token. In a mixture-of-experts model, only selected experts are activated for a given token. DeepSeek-V3 is a useful example of this direction: it has a very large total parameter count, but only a smaller portion of those parameters is activated per token. Techniques like sparsity, quantization, and compression help reduce the computation and memory needed during serving, making inference faster and cheaper. The goal is not to compress every model as much as possible. The goal is to balance quality, latency, cost, and deployment constraints so that the right model and serving strategy can be used for each workload.
KV cache optimization is another major part of this story. During text generation, large language models store key-value attention states so they do not have to recompute the entire context for every new token. This KV cache becomes especially important for long-context models, multi-turn conversations, retrieval-augmented generation, and agents. As context windows grow and workflows become more interactive, the KV cache can consume a large amount of memory.
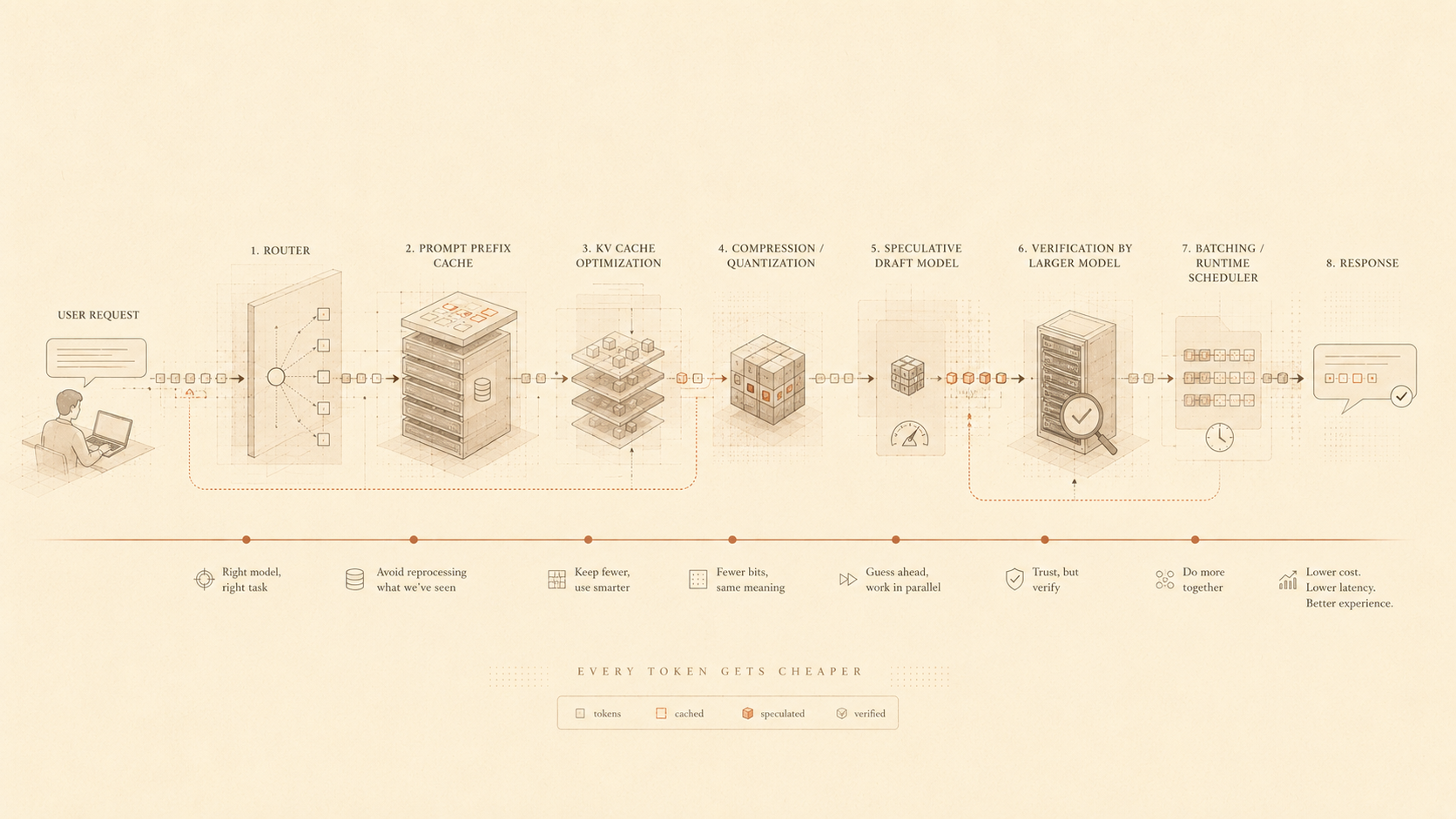
Modern inference systems increasingly look like operating systems. They manage memory, schedule work, reuse cached computation, batch requests, separate prefill from decoding, and decide what to keep or evict. The model itself still matters, but the runtime around the model is becoming just as important. A simple chatbot request may look like one prompt and one response. But under the hood, efficient inference requires a lot of orchestration. The system may batch multiple users together, reuse common prompt prefixes, cache previous computation, compress KV memory, speculate future tokens, and route the request to the right model. The software layer is trying to make token generation cheaper.
Speculative decoding is a good example of this mindset. Instead of asking the largest model to generate every token sequentially, a smaller or faster model can draft possible tokens first. The larger model then verifies those tokens. If the draft is accurate, the system can generate output faster while keeping the final behavior close to the larger model’s output. This matters because language models generate text one token at a time, and speculative decoding speeds this up by predicting ahead and checking the results.
Then there is notion of distillation. A large model can be used to generate training data or reasoning traces that help smaller models learn specialized behavior. The smaller model may not replace the frontier model entirely, but it can handle narrower tasks at much lower cost.
Agentic AI increases the demand further
This broader category of inference optimization is becoming increasingly important because agentic AI multiplies inference demand. A basic chatbot may answer a user once. An agent may plan, call tools, read results, revise its plan, call another tool, inspect files, search the web, generate code, test code, summarize findings, and then respond. Each step can involve one or more model calls. Agents are not just a product feature. They are inference loops. That has major implications for cost and infrastructure. If one user request turns into ten or twenty internal model calls, inference demand can grow much faster than visible user traffic. The software stack has to become far more selective: which model should handle each step, how much context should be passed, what can be cached, what can be summarized, and when should the system stop reasoning?
This is why smaller models and model routing are becoming strategically important. Not every task needs the largest frontier model. A simple classification, extraction, rewriting, search-ranking, or formatting task may be handled by a smaller model. Larger models can be reserved for tasks that require deeper reasoning, complex synthesis, or high-stakes judgment. Over time, AI systems may look less like one large model answering everything and more like a hierarchy of models, tools, caches, and routers.
The logical stack is therefore moving from model-centric AI to system-centric AI. In the model-centric view, progress comes mainly from building a better model. In the system-centric view, progress also comes from how the model is served, routed, compressed, cached, monitored, and combined with tools. This is similar to what happened in earlier computing eras. Once an expensive capability becomes widely used, the surrounding software stack becomes obsessed with efficiency.
The next phase of AI software will not be defined only by larger context windows or higher benchmark scores. It will also be defined by inference runtimes, model routers, cache layers, quantization methods, speculative decoding systems, agent orchestration, structured output engines, and cost-aware reasoning policies. From 2022 to 2023, software attention was largely focused on prompting, fine-tuning, and building applications on top of frontier models. In 2024, reasoning models and agentic workflows made inference more complex. By 2025 and 2026, the software stack is increasingly focused on making that complexity affordable. The core software transition is this: AI is moving from simply generating answers to managing inference as a scarce resource. The winners in this layer will be the companies that know when to use a large model, when to use a small model, when to cache, when to compress, when to reason longer, and when to stop. In the inference era, intelligence is not produced by the model alone. It is produced by the system around the model.
Sources
https://arxiv.org/html/2412.19437v1
https://arxiv.org/abs/2309.06180