Inside RAG — How It Really Works (And Why Most Projects Stall Before They Ship)
The gap between the RAG concept and production reality is where most projects quietly fail. Here's what the explanations usually skip.
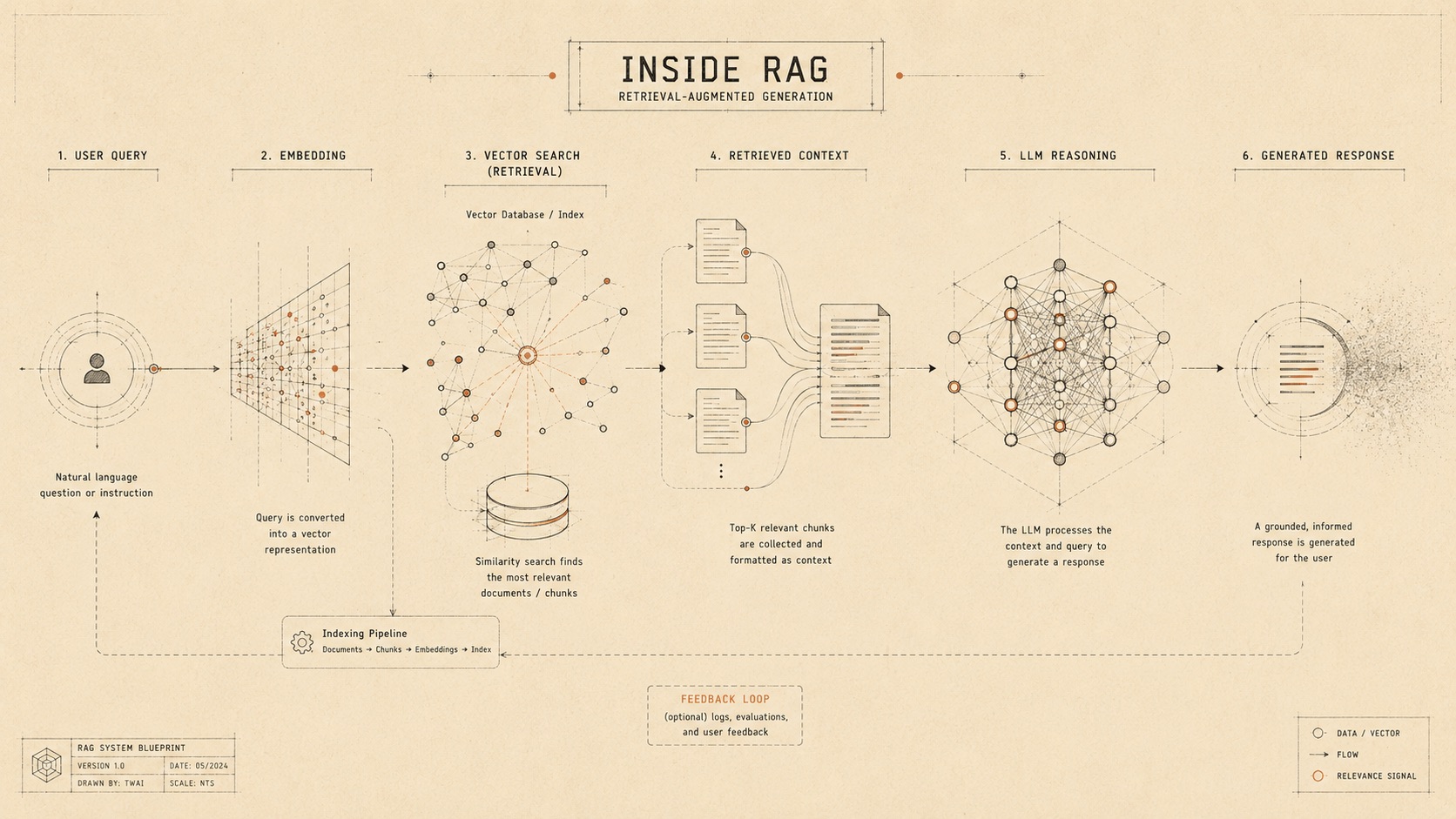
RAG seems pretty straightforward at first glance. At the heart of it, the philosophy is, split your documents into chunks, search for the ones that match the question, feed them into the prompt, and finally, have the LLM generate an answer.
But the interesting parts live in the nitty gritty details of how that retrieval piece actually functions. There are four main stages: chunking, embedding, retrieval, and generation. Each one has far more depth and gotchas than the typical quick-start tutorial ever mentions. Let's dive into the pipeline and look under the hood.
How RAG Actually Works
RAG has four core stages: preprocessing, embedding, retrieval, and generation. Some article claim 3 stages ignoring preprocessing. However, chunking in my opinion is stil a critical step worth considering a stage of its own.
Chunking
Chunking is breaking down documents into smaller pieces and doing it poorly quietly destroys answer quality. The default approach splitting text into fixed token chunks with some overlap is easy and works fine for clean, uniform content. But real-world documents (legal contracts, reports, API docs, policies) are full of tables, sections, and nested logic. Cut through the middle of a comparison table or separate a key paragraph from its heading, and the model gets incomplete fragments. It doesn't know what's missing, so it confidently hallucinates or gives half-answers. Chunks alone are still just raw text. To make them searchable by meaning instead of exact keywords, we convert them into embeddings.
Embedding: Turning Text into Meaning
An embedding is a numerical representation of text that captures semantic meaning. Instead of storing words directly, we transform each chunk into a vector, essentially a point in a high-dimensional space. Similar ideas end up close together, even if they use completely different wording. For example, a strong embedding model should understand that, "How do I cancel my subscription?", and "What's the process to terminate my plan?" are semantically similar despite sharing few exact words.
Retrieval
The query is first computed into a vector with same embedding model used in the step above. Than it is compared to a database of vectors from your documents. The system picks out the chunks that are most similar, usually using cosine similarity, and sends them along. This is what vector databases like Pinecone, Weaviate, Chroma, and pgvector are designed to do, quickly find the closest matches to millions of vectors in milliseconds.
Generation
The retrieved chunks are put together with the original question to create a prompt. The model then reads that context and generates its answer based on it. So, the final answer's quality depends on how good the retrieval was. A great model can't make up for bad retrieval, it might just make up more confidently with the wrong information.
Diving Deeper
Chunking: And how to think about good chunking strategy
Chunking, like I said, is a foundational step and sounds simple, but it's one of the biggest reasons RAG systems underperform in the real world. Before retrieval even begins, you have to break documents into smaller pieces and doing it poorly quietly destroys answer quality. Real-world documents (legal contracts, reports, API docs, policies) are full of tables, sections, and nested logic. Cut through the middle of a comparison table or separate a key paragraph from its heading, and the model gets incomplete fragments. It doesn't know what's missing, so it confidently hallucinates or gives half-answers.
Better methods respect the document's actual structure:
- Semantic chunking splits at meaning boundaries instead of arbitrary token counts.
- Hierarchical chunking keeps parent-child relationships, so a subsection chunk still knows it belongs under a larger section.
Studies show chunking strategy can account for up to ~35% of final answer quality, and smarter approaches have improved retrieval accuracy by 9+ percentage points in benchmarks.
When deciding the chunk size, you should invert the problem statement. Instead of what is the right size, think through, "What does a good answer to our most common questions actually need?" What does a good answer to our most common questions actually need? Customer support FAQs often need small, self-contained chunks. Legal or technical docs usually require larger, connected chunks that preserve context and relationships. Get chunking right (guided by your content and use cases), and everything downstream retrieval, generation, and trust becomes much easier. Get it wrong, and no fancy reranker or prompt will fully fix it.
Embedding: And how to chose the right model to embed
No single embedding model is best for every workload. Some optimize for multilingual support, some for retrieval precision, and others for cost or self-hosting flexibility.
Popular Embedding Models in 2026
| Model | Strengths | Best For | Notes |
OpenAI text-embedding-3-large | Reliable all-round performance across retrieval, clustering, and classification | General production use | 3072 dimensions (reducible), strong ecosystem support, easy default choice |
Google Gemini Embedding | Excellent multilingual and long-context performance | Global and multimodal applications | One of the strongest overall benchmark performers |
Voyage AI (voyage-3 / voyage-3-large) | Exceptional retrieval quality | High-precision search | Particularly strong for legal, finance, and code retrieval |
Cohere Embed v4 | Strong multilingual + multimodal support | International apps and mixed media | Good balance of quality and flexibility |
Qwen3-Embedding-8B | High benchmark performance with self-hosting | Privacy and cost control | Strong open-source option |
NV-Embed-v2 | Excellent retrieval quality | Self-hosted enterprise workloads | Competitive with top proprietary models |
BGE-M3 | Strong multilingual support (100+ languages) | Multilingual RAG systems | Production favorite in open-source stacks |
Pro tip: Always evaluate embeddings on your own queries and documents, not just public benchmarks like MTEB. A model that ranks highest overall may still underperform on your specific domain. Many teams gain noticeable retrieval improvements simply by switching to a model better aligned with their data.
Retrieval: And how to deal with quality problem
Even with good chunking, basic vector similarity retrieval has its limits. It can spot text that's semantically similar, but it doesn't grasp intent, how recent something is, or the difference between a document mentioning a topic and one that answers a specific question about it.
Most RAG systems in production have moved beyond just retrieving information in one go. Here are some common approaches:
Hybrid retrieval mixes dense vector search with sparse keyword search (usually using BM25). Vector search focuses on understanding the meaning, while BM25 matches exact terms—like product names, error codes, or specific identifiers that embeddings might not always capture. Combining both methods with reciprocal rank fusion usually gives better results than using either one alone, especially when dealing with technical data where accuracy is key.
Reranking involves a second step after the initial retrieval. A cross-encoder model, which reads the query and each candidate chunk together instead of separately, scores relevance more accurately than just using cosine similarity. Cohere's Rerank and similar models have become a standard addition to serious production systems because they significantly improve retrieval precision without adding much latency.
Query rewriting helps bridge the gap between how users ask questions and how the source documents are written. For example, a user asking "why did my transaction get declined?" might get better results if the system first rewrites the query to something like "payment failure reasons" or "transaction decline conditions." Some systems use a small LLM call specifically for this step before the retrieval process begins.
These methods aren't new. They're what separates a demo that works well from a system that can handle real-world data effectively.
Why Projects Stall
In RAG post-mortems, the common issue is that the system worked great during development but didn't perform as well when tested with real data.
Development usually happens on clean, well-organized documents. But when it comes to production, we're connecting to the real knowledge base—internal wikis that have been around for five years, policy documents with three versions that are all still in use, and support articles that were accurate back in 2022 and haven't been updated since. All of this gets indexed. The retriever doesn't know which content is up-to-date, which is contradictory, or which should have been removed a year ago.
The model doesn't know either. It combines information from all the retrieval sources. When that mix includes both old and new content at the same time, the output looks authoritative but is partially incorrect. This is more harmful than a system that fails visibly because it fails quietly, and users don't realize it until something goes wrong later on.
The fix most teams skip: Make data quality a priority, not just something you do after the fact. Before you start working with embeddings, take a look at the corpus. Delete or archive documents that are outdated. Resolve any contradictions. Add metadata—like document dates, who owns it, its status, and which product version it applies to—so retrieval can filter by recency or scope when it's important. RAG is how you make your knowledge base work. If your knowledge base is broken, RAG just makes the broken parts easier to access.
What Context Windows Actually Changed — And What They Didn't
When Gemini 2.5 Pro came out with a 1-million-token context window in early 2025, the "RAG is dead" argument resurfaced. If you can fit your entire knowledge base into a single prompt, why bother with a retrieval pipeline?
For small, stable corpora—a few hundred documents, under about 500K tokens—that argument makes sense. Putting everything into a long-context prompt gets rid of retrieval errors, the need to chunk things, and the complexity of the pipeline. For those situations, it's often the best option. The developer who spent two weeks building a RAG pipeline for a 150K-token corpus could have finished in an afternoon by doing exactly this.
When dealing with bigger, more active datasets, there are still three challenges that context length alone can't solve.
Cost. Sending 1–2 million tokens for every query can get pricey, especially when you're dealing with a lot of data. Retrieval, on the other hand, only sends what's really needed—usually just a few thousand tokens per query.
Attention fading. Studies on models that handle long contexts have shown that the more context you give them, the harder it is to remember the information. This is especially true for details that are tucked away in the middle of a long document. A model that reads 1 million tokens doesn't focus evenly on everything. Retrieval, however, focuses on the most important stuff instead of spreading attention too thin.
Keeping things up-to-date. A RAG pipeline keeps track of new documents as they come in. A long-context approach needs you to manually manage what goes into each prompt as the knowledge base changes. At a large scale, that's not practical.
Context windows and RAG aren't trying to replace each other. They're different tools with different trade-offs in terms of cost and complexity, depending on how big the data is.
GraphRAG: When the Answer is Hidden in the Documents
Standard vector RAG works on the idea that the information you need to answer a question is mostly there, mostly intact, in one or a few chunks of a document. Just find the right chunks, and you've got it.
But that idea doesn't always work for important kinds of questions. For example, "What risk factors seem to be common in our top loan segments?" isn't about finding similar text. The answer is spread out across many documents and needs to connect different things—like borrowers, loan types, collateral categories, and economic conditions—that no single chunk has all at once.
GraphRAG, which Microsoft open-sourced in 2024 and has since seen rapid adoption in regulated industries, handles this by indexing knowledge as a graph of entities and relationships rather than a flat vector index. Documents are processed to extract named entities and the relationships between them. Retrieval becomes graph traversal — following connections between nodes rather than scanning for vector similarity.
The practical tradeoff is real: GraphRAG is more expensive to build and maintain than standard RAG, and it requires an extraction pipeline that understands your domain well enough to identify the right entities and relationships. But for corpora where the meaningful structure is relational rather than textual, standard RAG hits a ceiling that better chunking and reranking can't fix.
Mature production systems increasingly route queries rather than committing to one retrieval strategy. A question about a specific policy document goes to standard RAG. A question about patterns across the portfolio goes to GraphRAG. The orchestration layer decides which path fits which query type.
Before You Build
| Question | Implication |
| Corpus under ~500 docs? | Try a long-context prompt first — you may not need a pipeline |
| Data changes frequently? | RAG handles freshness better than long-context management |
| Is your data actually clean? | Audit before indexing — retrieval amplifies data problems |
| Questions connect entities across many documents? | Evaluate GraphRAG alongside standard retrieval |
| Answers need traceable sources? | RAG makes citations and auditability direct |
| Users ask with varied phrasing? | Plan for query rewriting and hybrid retrieval from the start |
The technical pieces of RAG are well understood at this point. Embeddings, vector databases, chunking strategies — there's good tooling for all of it. What still trips teams up is the assumption that the hard part is the infrastructure. It isn't. The hard part is the data underneath it, and the retrieval design on top of it. Get those right, and the rest follows.
Up next — Part 3: Fine-Tuning in 2026: Bloomberg spent roughly $10 million on it. You can now get started for under $100. What changed, and when does fine-tuning actually make sense?
Key Takeaways
- RAG has three steps — embed, retrieve, generate — but production quality lives in the details of each
- Chunking strategy should follow document structure and query type, not a fixed token count
- Hybrid retrieval and reranking are now near-standard in serious deployments; plain vector similarity has a ceiling
- Data quality is the leading cause of RAG failures — retrieval amplifies whatever is in the index, good or bad
- Long-context prompts are a legitimate alternative for small, stable corpora; RAG wins on cost and freshness at scale
- GraphRAG handles relationship-dense queries that flat vector search structurally cannot
Sources
⁵ Practitioner accounts and production deployment reports from 2025-2026; see *What Is RAG in AI? 2026 Production Guide*, MarsDevs, and *RAG vs Fine-Tuning vs AI Agents*, GeekyAnts. Practitioner surveys, not peer-reviewed studies; reported failure rates vary across sources.
⁶ Google Blog: *Gemini 2.5 Pro*, March 2025; 2M-token variant announced subsequently
⁷ *Why Gemini 1.5 and Other Large Context Models Are Bullish for RAG*, Medium/Enterprise RAG, February 2024; Vectorize.IO analysis
⁸ Microsoft Research: github.com/microsoft/graphrag, open-sourced 2024