RAG vs. Fine-Tuning — The Question Every AI Builder Gets Wrong
AI models don't know your private data. Two approaches have been the standard answer. In 2026, a third matters just as much.
LLMs are trained on publicly available data and broad general knowledge. They're remarkably capable across a wide range of tasks. However, they do not inherently understand the proprietary knowledge that defines how your company actually operates. Internal policies, architectural decisions, pricing structures, contract terms, issue tracking systems, and recent product changes all exist outside the model's built-in knowledge. This is where commercial adoption often runs into real limitations. When customers ask company-specific questions, the model frequently lacks a reliable source of truth. In those moments, it does what it was designed to do: generate the most plausible answer based on patterns. Sometimes that answer is right. Often, it is not.
This is fundamentally a knowledge problem, not purely a model quality problem. And it is one that nearly every organization building customer-facing systems eventually encounters.
Take a common scenario: a customer asks your assistant, "What's our refund policy for enterprise subscriptions?" The system responds immediately and confidently, but the answer is incorrect. That is where trust begins to break.
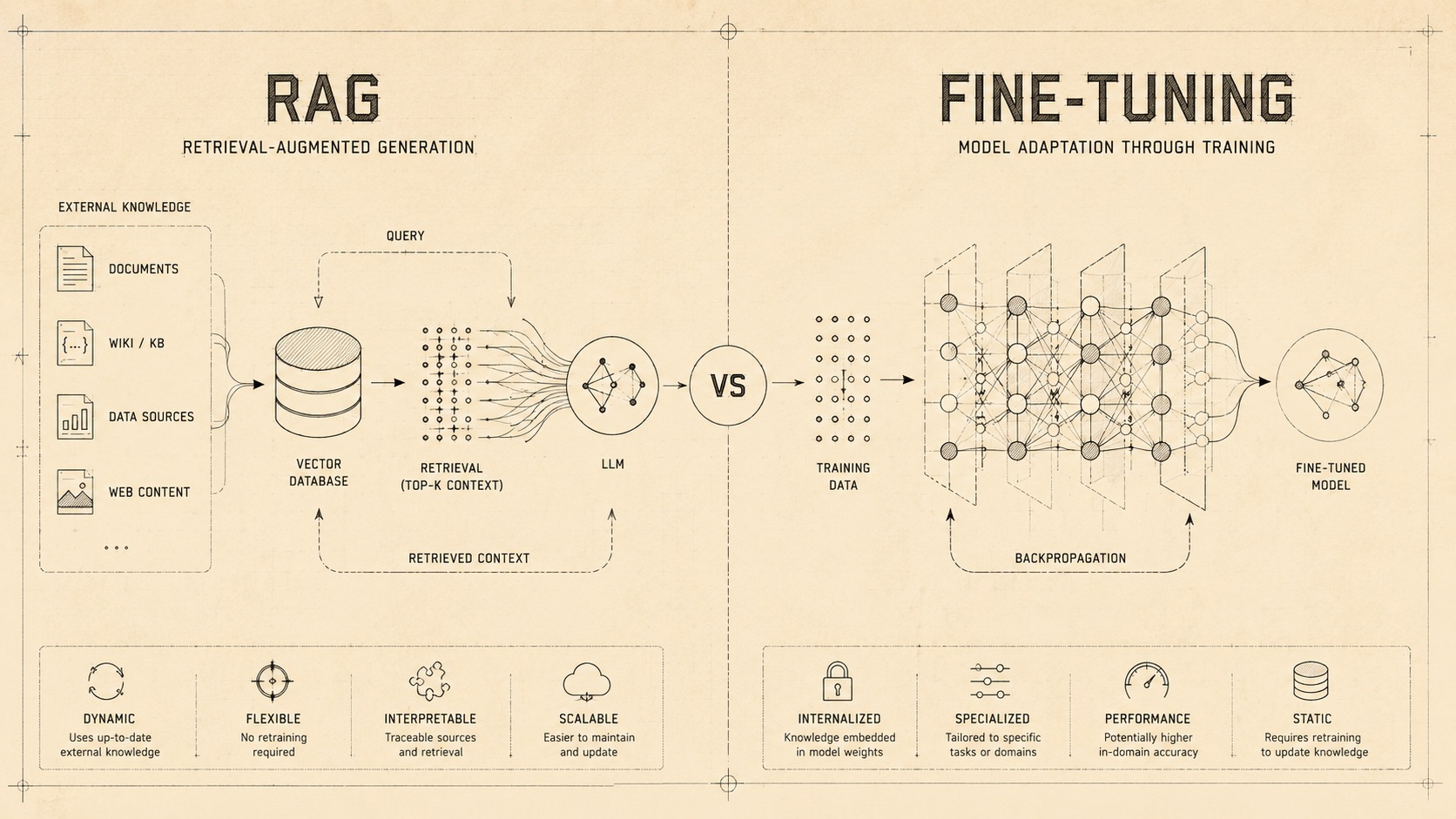
Two approaches have traditionally been the standard response: Fine-Tuning and Retrieval-Augmented Generation (RAG). These days there is also a third layer: Agentic RAG. Let's talk about first two as they still remain essential.
Fine-Tuning: Retraining the Brain
Fine-tuning takes a pre-trained model and continues training it on your proprietary data, updating the model's internal weights, the mathematical structures that shape how it reasons and responds. Think of it like a doctor completing specialized residency training. After years of cardiology practice, they are not constantly referencing manuals. That expertise becomes embedded in how they think. Fine-tuning works similarly.
Rather than retrieving information externally, the model internalizes patterns, reasoning styles, and domain knowledge directly into its structure.
Bloomberg's BloombergGPT is a strong example. Bloomberg trained a 50-billion-parameter model on 363 billion tokens of financial data so that financial reasoning lived directly at the weight level instead of relying on external retrieval. Legal organizations use similar approaches to shape models around highly specific writing styles, citation structures, and domain workflows.
| Aspect | Fine-Tuning |
| Strength | Behavioral consistency |
| Best For | Reliably producing structured outputs, reasoning within narrow domains, and maintaining highly specialized behavioral patterns |
| Core Advantage | Builds capabilities directly into the model itself rather than depending primarily on prompting |
| Weakness | Knowledge freezes once training ends |
| Limitation | Changes in policies, products, or pricing require retraining |
| Operational Cost | Retraining introduces substantial cost, engineering complexity, and maintenance overhead |
| Risk | Can hallucinate with greater confidence because knowledge feels internal and authoritative |
| Transparency Issue | Often cannot cite external sources since answers come from model weights rather than live documents |
| Failure Mode | Inaccuracies embedded during training may be delivered with the same certainty as correct information |
RAG: Giving the Brain a Library Card
RAG approaches the problem differently. Rather than modifying the model itself, it builds a retrieval pipeline around it. When a user asks a question, the system searches a private knowledge base, such as internal documentation, contracts, support materials, product specifications, or policy documents, retrieves the most relevant information, and injects that content directly into the model's context.
In practice, the workflow becomes:
"Here is the user's question. Here are the relevant internal documents. Answer using these."
The model does not memorize company knowledge permanently. Instead, it accesses what it needs in real time. That distinction is critical.
Notion AI is a useful example. Rather than depending entirely on pre-trained memory, it indexes workspace content and retrieves relevant pages before generating responses. This allows answers to remain current while also improving traceability.
| Aspect | RAG (Retrieval-Augmented Generation) |
| Strengths | Keeps knowledge current without retraining |
| Key Advantages | Allows systems to cite sources, improves auditability, and significantly reduces hallucinations by grounding outputs in real documentation |
| Core Benefit | Continuously operationalizes live or updated knowledge bases rather than static model weights |
| Constraint | Reliability depends entirely on the quality of the underlying knowledge base |
| Limitation | Outdated documentation, fragmented policy changes, or contradictory internal sources can still produce flawed answers |
| Operational Dependency | Does not fix poor information hygiene; it only surfaces and operationalizes existing information |
| Risk | Weak, inconsistent, or stale source material can still lead to inaccurate outputs |
| Transparency Advantage | Provides external references and source traceability, improving trust and verification |
This is how to remember the distinction
RAG is for knowledge. Fine-tuning is for behavior.
This remains one of the most practical distinctions.
RAG is best when the system needs access to dynamic, changing information such as policies, pricing, product details, or operational knowledge. For most enterprise deployments, including customer support assistants, internal search systems, and document Q&A, RAG is typically faster to implement, less expensive to maintain, and easier to audit.
Fine-tuning is best when the system needs to consistently behave in specialized ways, whether that means reasoning deeply in a niche domain, maintaining strict formatting, or embedding domain-specific fluency that prompts alone cannot reliably sustain.
Fine-tuning becomes more compelling when behavior itself is the competitive advantage.
Bloomberg needed financial reasoning embedded deeply into the model.
GitHub Copilot needed code generation performance fast enough that retrieval latency would compromise usability.
For most teams, however, the practical path is simpler: Start with RAG.
Agentic RAG: The third option, best of both worlds
For years, "RAG or fine-tuning" was the dominant framing. By 2026, that framing is increasingly incomplete. The most capable production systems rarely rely on one approach alone. Instead, they combine both inside larger reasoning systems that can plan, retrieve, evaluate, and iterate dynamically.
This is where agentic systems enter. Agents do not replace RAG. They do not replace fine-tuning. They provide the operational loop that allows both to function together more intelligently. Fine-tuning shapes behavior. RAG provides knowledge. Agents orchestrate decision-making across both.
That third layer is becoming increasingly important in modern deployment architecture. But before understanding agents, it is necessary to first understand how RAG actually functions in production, because the gap between conceptual retrieval and real-world implementation is where most systems either succeed or fail.
Up next — Part 2: Inside RAG: embeddings, chunking, vector databases, why most RAG projects stall, and what million-token context windows actually changed.
Key Takeaways
- AI models don't know your private data. This is a knowledge problem, not a quality problem.
- Fine-tuning changes how a model thinks. RAG changes what it can access.
- RAG is the right default for most business use cases.
- Fine-tuning is for behavior: output format, reasoning style, domain fluency.
- Agents add a third layer that orchestrates both.
Sources
² Wu, S., et al. *BloombergGPT: A Large Language Model for Finance.* arXiv:2303.17564, 2023
³ Notion Engineering Blog: *Building and Scaling Notion's Data Lake*, July 2024; ZenML LLMOps Database: *Notion: Scaling Data Infrastructure for AI Features and RAG*